Following on from my recent post about doing something this year, I’m committing to doing 12 months of “101”s; posts and projects themed at beginning something new (or reasonably new) to me.
January is all about node, and I started with a basic intro, then cracked open a basic web server with content-type manipulation and basic routing, and the last one was a basic API implementation
Appharbor, Azure, and Heroku
Being a bit of a cocky git I said on twitter at the weekend:
Working on a blog post about easy hosting options; essentially “git push [azure/appharbor/heroku] master” stretched over a few pages..
— Robin Osborne (@rposbo) January 12, 2013
It’s not quite that easy, but it’s actually not far off!
Deployment & Hosting Options
These are not the only options, but just three that I’m aware of and have previously had a play with. A prerequisite for each of these – for the purposes of this post – is using git for version control since AppHarbor, Azure, and Heroku support git hooks and remotes; this means essentially you can submit your changes directly to your host, which will automatically deploy them (if pre-checks pass).
I’ll be using the set of files from my previous API post for this one, except I need to change the facility to pass in command line args for the api key to instead take it from a querystring parameter.
The initial files are the same as the last post and can be grabbed from github
Those changes are:
app.js (removed lines about getting value from command line):
[js]var server = require("./server"),
router = require("./router"),
requestHandlers = require("./requestHandlers");
// only handling GETs at the moment
var handle = {}
handle["favicon.ico"] = requestHandlers.favicon;
handle["product"] = requestHandlers.product;
handle["products"] = requestHandlers.products;
var port = process.env.PORT || 3000;
server.start(router.route, handle, port);[/js]
server.js (added in querystring param usage):
[js highlight=”7″]var http = require("http"),
url = require("url");
function start(route, handle, port) {
function onRequest(request, response) {
var pathname = url.parse(request.url).pathname;
var apiKey = url.parse(request.url, true).query.key;
route(handle, pathname, response, apiKey);
}
http.createServer(onRequest).listen(port);
console.log("Server has started listening on port " + port);
}
exports.start = start;[/js]
The “.query” returns a querystring object, which means I can get the parameter “key” by using “.key” instead of something like [“key”].
Ideal scenario
In the perfect world all I’d need to do is something like:
[code]git add .
git commit -m "initial node stuff"
git push {azure/appharbor/heroku/whatever} master
…..
done
…..
new site deployed to blahblah.websitey.net
…..
have a lovely day
[/code]
and I could pop off for a cup of earl grey.
In order to get to that point there were a few steps I needed to take for each of the three hosts.
Appharbor
Getting started
First things first; go and sign up for a free account with AppHarbor.
Then set up a new application in order to be given your git remote endpoint to push to.
I’ve previously had a play with Appharbor, but this is the first time I’m using it for more than just a freebie host.
Configuring
It’s not quite as simple as I would have liked; there are a couple of things that you need to bear in mind. Although Appharbor supports node deployments they are primarily a .Net hosting service and use Windows hosting environments (even though they’re on EC2 as opposed to Azure). Running node within iis means that you need to supply a web.config file and give it some IIS-specific info.
The config file I had to use is:
[xml highlight=”3,9″]<configuration>
<system.web>
<compilation batch="false" />
</system.web>
<system.webServer>
<handlers>
<add name="iisnode" path="app.js" verb="*" modules="iisnode" />
</handlers>
<iisnode loggingEnabled="false" />
<rewrite>
<rules>
<rule name="myapp">
<match url="/*" />
<action type="Rewrite" url="app.js" />
</rule>
</rules>
</rewrite>
</system.webServer>
</configuration>[/xml]
Most of that should be pretty straightforward (redirect all calls to app.js), but notice the lines about compilation and logging; the permissions under which the appharbor deployment process runs for node projects doesn’t have access to the filesystem so can’t create anything in a “temp” dir (precompilation) nor write any log files upon errors. As such, you need to disable these.
You could also enable file system access and disable precompilation within your application’s settings – as far as I can tell, it does the same thing.
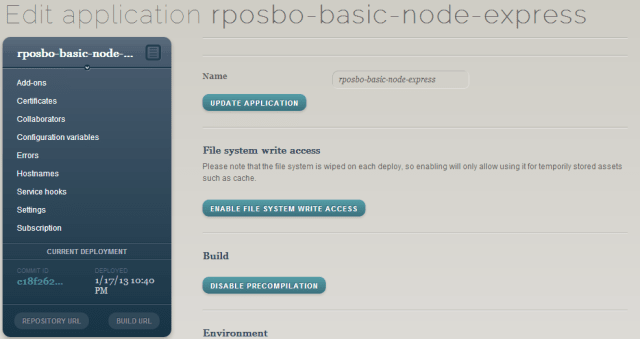
Deploying
Commit that web.config to your repo, add a remote for appharbor, then push to it – any branch other than master, default, or trunk needs a manual deploy instead of it happening automatically, but you can specify the branch name to track within your appharbor application settings; I put in the branch name “appharbor” that I’ve been developing against and it automatically deploys when I push that branch or master, but not any others.
You’ll see your dashboard updates and deploys (automatic deployment if it’s a tracked branch):
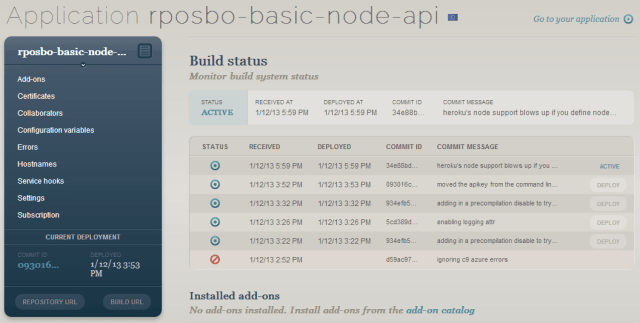
And then you can browse to your app:
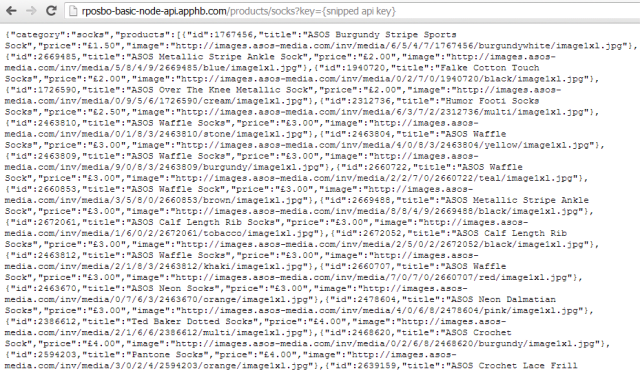
Azure
Getting started
Again, first step is to go and sign up for Azure – you can get a free trial, and if you only want to host up to 10 small websites then it’s completely free.
You’ll need to set up a new Azure website in order to be given your git remote endpoint to push to.
Configuring
This is pretty similar to the AppHarbor process in that Azure Websites sit on Windows and IIS, so you need to define a web.config to set up IIS for node. The same web.config works as for AppHarbor.
Deploying
Although you can push to Appharbor from any branch and it will only deploy automatically from the specific tracked branch, you can’t choose to manually deploy from within azure, so you either need to use [code]git push azure {branch}:master[/code] (assuming your remote is called “azure”) or you can define your tracked branch in the configuration section:
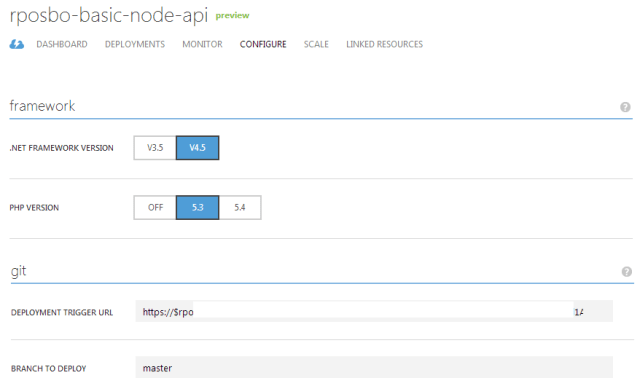
Following a successful push your dashboard updates and deploys:
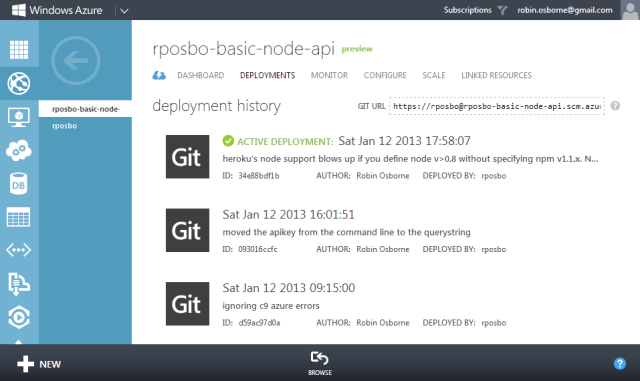
And then your app is browsable:
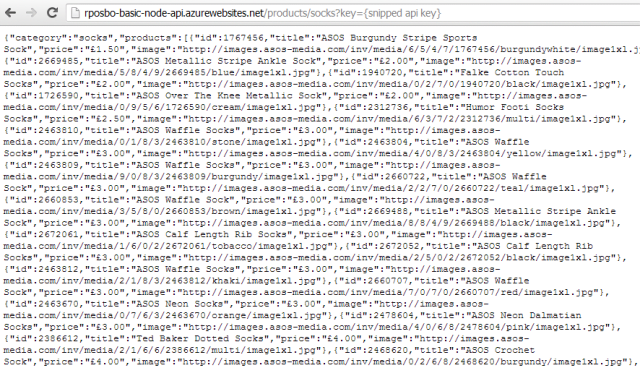
Heroku
Getting started
Sign up for a free account.
Configuring
Heroku isn’t Windows based as it’s aimed at hosting Ruby, Node.js, Clojure, Java, Python, and Scala. What this means for our node deployment is that we don’t need a web.config to get the application running on Heroku. It’s still running on Amazon’s EC2 as far as I can tell though.
However, we do need to jump through several other strange hoops:
Procfile
The procfile is a list of the “process types in an application. Each process type is a declaration of a command that is executed when a process of that process type is executed.” These can be arbitrarily named except for the “web” one which handles HTTP traffic.
For node, this Procfile needs to be:
Procfile:
[code]web: node app.js[/code]
Should I want to pass in command line arguments, as in the previous version of my basic node API code, I could do it in this file i.e. [code]web: node app.js mYAp1K3Y[/code]
Deploying
Heroku Toolbelt
There’s a command line tool which you need to install in order to use Heroku, called the Toolbelt; this is the Heroku client which allows you to do a lot of powerful things from the command line including scaling up and down, and start and stopping your application.
Instead of adding heroku as a git remote yourself you need to open a command line in your project’s directory and run [code]heroku login[/code]and then[code]heroku create[/code]
Your application space will now have been created within Heroku automatically (no need to log in and create one first) as well as your git remote; this will have the default name of “heroku”
Deploying code is still the same as before [code]git push heroku master[/code]
In Heroku you do need to commit to master to have your code built and deployed, and I couldn’t find anywhere to specify a different tracking branch.
Before that we need to create the last required file:
package.json:
[js]{
"name": "rposbo-basic-node-hosting-options",
"author": "Robin Osborne",
"description": "the node.js files used in my blog post about a basic node api being hosted in various places (github, azure, heroku)",
"version": "0.0.1",
"engines": {
"node": "0.8.x",
"npm": "1.1.x"
}
}[/js]
This file is used by npm (node package manager) to install the module dependencies for your application; e.g. express, jade, stylus. Even though our basic API project has no specifc dependencies, the file is still required by Heroku in order to define the version of node and npm to use (otherwise your application simply isn’t recognised as a node.js app).
Something to consider is that Heroku doesn’t necessarily have the same version of node installed as you might; I defined 0.8.16 and received an error upon deployment which listed the available versions (the highest at time of writing is 0.8.14). I decided to define my required version as “0.8.x” (any version that is major 0 minor 8).
However, if you define a version of node in the 0.8.x series you must also define the version of npm. A known issue, apparently. Not only that, it needs to be specifically “1.1.x”.
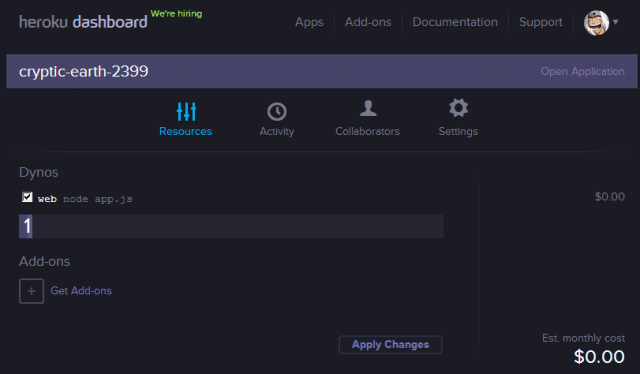
Add these settings into the “engines” section of the package.json file, git add, git commit, and git push to see your dashboard updated:
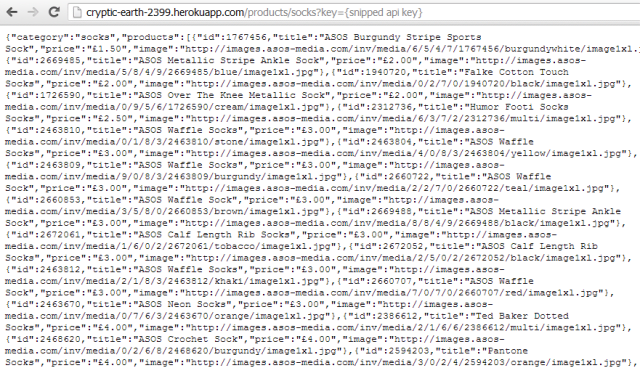
And then your app – with a quite random URL! – is available:
If you have problems pushing due to your existing public keys not existing within heroku, run the following to import them [code]heroku keys:add[/code]
You can also scale up and down your number of instances using the Heroku client: [code]heroku ps:scale web=1[/code]
Debugging
The Heroku Toolbelt is a really useful client to have; you can check your logs with [code]heroku logs[/code] and you can even leave a trace session open using [code]heroku logs –tail[/code], which is amazing for debugging problems.
The error codes you encounter are all listed on the heroku site as is all of the information on using the Heroku Toolbelt logging facility.
A quick one: if you see the error “H14”, then although your deployment may have worked it hasn’t automatically kicked off a web role – you can see this where it says “dyno=” instead of “dyno=web.1”; you just need to run the following command to start one up: [code]heroku ps:scale web=1[/code]
Also – make sure you’ve created a Procfile (with capitalised “P”) and that it contains [code]web: node app.js[/code]
Summary
Ok, so we can now easily deploy and host our API. The files that I’ve been working with throughout this post are on github; everything has been merged into master (both heroku files and web.config) so it can be deployed to any of these hosts.
There are also separate branches for Azure/Appharbor and Heroku should you want to check the different files in isolation.
Next Up
Node packages!