So what is NuGet, anyway?
Intro
When working with shared functionality across multiple .Net projects and team members, historically your options are limited to something like;
- Copy a dll containing the common functionality into your solution
- Register the dll into the GAC on whichever machine it needs to run
- Reference the project itself within your solution
There are several problems with these such as;
- ensuring all environments have the correct version of the dll as well as any dependencies already installed
- tight dependencies between projects, potentially breaking several when the shared project is updated
- trust – is this something you’re willing to install into a GAC if it’s from a 3rd party?
- so many more, much more painful, bad bad things
So how can you get around this pain?
I’m glad you asked.
Treasure! Rubies, Gems, oh my.

The ruby language has had this problem solved for many, many years – since around 2004, in fact.
Using the gem command you could install a ruby package from a central location into your project, along with all dependencies, e.g.:
gem install rails --include-dependencies
This one would pull down rails as well as packages that rails itself depended on.
You could search for gems, update your project’s gems, remove old versions, and remove the gem from your project entirely; all with minimal friction. No more scouring the internets for information on what to download, where to get it from, how to install it, and then find out you need to repeat this for a dozen other dependent packages!
You use a .gemspec file to define the contents and meta data for your gem before pushing the gem to shared repository.
Pe(a)rls of Wisdom

Even ruby gems were borne from a frustration that the ruby ecosystem wasn’t supported as well as Perl; Perl had CPAN (Comprehensive Perl Archive Network) for over a DECADE before ruby gems appeared – it’s been up since 1995!
Nubular / Nu

If Perl had CPAN since 1995, and ruby had gems since 2005, where is the .Net solution?
I’d spent many a project forgetting where I downloaded PostSharp from or RhinoMocks, and having to repeat the steps of discovery before I could even start development; leaving the IDE in order to browse online, download, unzip, copy, paste, before referencing within the IDE, finding there were missing dependencies, rinse, repeat.
Around mid-2010 Dru Sellers and gang (including Rob Reynolds aka @ferventcoder) built the fantastic “nu[bular]” project; this was itself a ruby gem, and could only be installed using ruby gems; i.e., to use nu you needed to install ruby and rubygems.
Side note: Rob was no stranger to the concept of .Net gems and has since created the incredible Chocolatey apt-get style package manager for installing applications instead of just referencing packages within your code projects, which I’ve previously waxed non-lyrical about
Once installed you were able to pull down and install .Net packages into your projects (again, these were actually just ruby gems). At the time of writing it still exists as a ruby gem and you can see the humble beginnings and subsequent death (or rather, fading away) of the project over on its homepage (this google group).
I used this when I first heard about it and found it to be extremely promising; the idea that you can centralise the package management for the .Net ecosystem was an extremely attractive proposition; unfortunately at the time I was working at a company where introducing new and exciting (especially open source) things was generally considered Scary™. However it still had some way to go.
NuPack

In October 2006 Nu became Nu v2, at which point it became NuPack; The Epic Trinity of Microsoft awesomeness – namely Scott Guthrie, Scott Hanselman, and Phil Haack – together with Dave Ebbo and David Fowler and the Nubular team took a mere matter of months to create the first fully open sourced project that was central to an MS product – i.e., VisualStudio which was accepted into the ASP.Net open source gallery in Oct 2006
It’s referred to as NuPack in the ASP.MVC 3 Beta release notes from Oct 6 2010 but underwent a name change due to a conflict with an existing product, NUPACK from Caltech.
NuGet! (finally)

There was a vote, and if you look through the issues listed against the project in codeplex you can see some of the other suggestions.
(Notice how none of the names available in the original vote are “NuGet”..)
Finally we have NuGet! The associated codeplex work item actually originally proposed “Nugget”, but that was change to NuGet.
Okay already, so what IS NuGet?!
Essentially the same as a gem; an archive with associated metadata in a manifest file (.nuspec for nuget, .gemspec for gems). It’s blindingly simple in concept, but takes a crapload of effort and smarts to get everything working smoothly around that simplicity.
All of the details for creating a package are on the NuGet website.
Using NuGet at Mailcloud
We decided to use MyGet initially to kick off our own private nuget feed (but will migrate shortly to a self-hosted solution most likely; I mean, look at how easy it is! Install-Package NuGet.Server, deploy, profit!)
The only slight complexity was allowing the private feed’s authentication to be saved with the package restore information; I’ll get on to this shortly as there are a couple of options.
Creating a package
Once you’ve created a project that you’d like to share across other projects, it’s simply a matter of opening a prompt in the directory where your csproj file lives and running:
nuget spec
to create the nuspec file ready for you to configure, which looks like this:
<?xml version="1.0"?>
<package >
<metadata>
<id>$id$</id>
<version>$version$</version>
<title>$title$</title>
<authors>$author$</authors>
<owners>$author$</owners>
<licenseUrl>http://LICENSE_URL_HERE_OR_DELETE_THIS_LINE</licenseUrl>
<projectUrl>http://PROJECT_URL_HERE_OR_DELETE_THIS_LINE</projectUrl>
<iconUrl>http://ICON_URL_HERE_OR_DELETE_THIS_LINE</iconUrl>
<requireLicenseAcceptance>false</requireLicenseAcceptance>
<description>$description$</description>
<releaseNotes>Summary of changes made in this release of the package.</releaseNotes>
<copyright>Copyright 2014</copyright>
<tags>Tag1 Tag2</tags>
</metadata>
</package>
Fill in the blanks and then run:
nuget pack YourProject.csproj
to end up with a .nupkg file in your working directory.

As previously mentioned, this is just an archive. As such you can open it yourself in 7Zip or similar and find something like this:
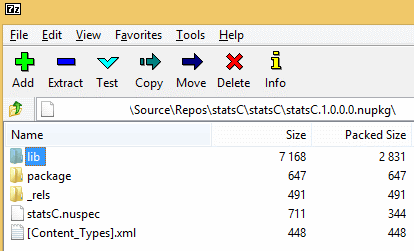
Your compiled dll can be found in the lib dir.
Pushing to your package feed
If you’re using MyGet then you can upload your nupkg via the MyGet website directly into your feed.
If you like the command line, and I do like my command line, then you can use the nupack command to do this for you:
nuget push MyPackage.1.0.0.nupkg <your api key> -Source https://www.myget.org/F/<your feed name>/api/v2/package
Once this has completed your package will be available at your feed, ready for referencing within your own projects.
Referencing your packages
If you’re using a feed that requires authentication then there are a couple of options.
Edit your NuGet sources (Options -> Package Manager -> Package Sources) and add in your main feed URL, e.g.
http://www.myget.org/F/<your feed name>/
If you do this against a private feed then an attempt to install a package pops up a windows auth prompt:
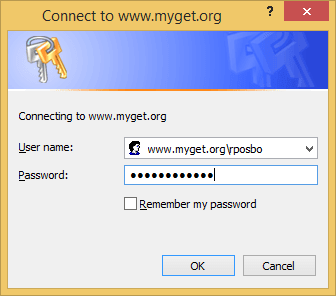
This will certainly work locally, but you may have problems when using a build server such as teamcity or VisualStudio Online due to the non-interactive authentication.
One solution to this is to actually include your password (in plain text – eep!) in your nuget.config file. To do this, right click your solution and select “Enable Package Restore”.
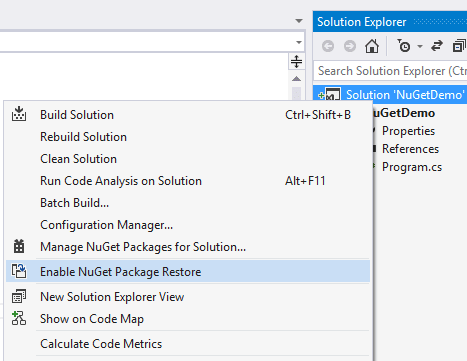
This will create a .nuget folder in your solution containing the nuget executable, a config file and a targets file. Initially the config file will be pretty bare. If you edit it and add in something similar to the following then your package restore will use the supplied credentials for the defined feeds:
<?xml version="1.0" encoding="utf-8"?>
<configuration>
<solution>
<add key="disableSourceControlIntegration" value="true" />
</solution>
<packageSources>
<clear />
<add key="nuget.org" value="https://www.nuget.org/api/v2/" />
<add key="Microsoft and .NET" value="https://www.nuget.org/api/v2/curated-feeds/microsoftdotnet/" />
<add key="MyFeed" value="https://www.myget.org/F/<feed name>/" />
</packageSources>
<disabledPackageSources />
<packageSourceCredentials>
<MyFeed>
<add key="Username" value="myusername" />
<add key="ClearTextPassword" value="mypassword" />
</MyFeed>
</packageSourceCredentials>
</configuration>
So we resupply the package sources (need to clear them first else you get duplicates), then add a packageSourceCredentials section with an element matching the name you gave your packageSource in the section above it.
Alternative Approach
Don’t like plain text passwords? Prefer auth tokens? Course ya do. Who doesn’t? In that case, another option is to use the secondary feed URL MyGet provides instead of the primary one, which contains your auth token (which can be rescinded at any time) and looks like:
https://www.myget.org/F/<your feed name>/auth/<auth token>/
Notice the extra “auth/blah-blah-blah” at the end of this version.
Summary
NuGet as a package manager solution is pretty slick. And the fact that it’s open sourced and can easily be self-hosted internally means it’s an obvious solution for managing those shared libraries within your project, personal or corporate.
http://weblogs.asp.net/bsimser/archive/2010/10/06/unicorns-triple-rainbows-package-management-and-lasers.aspx
http://devlicio.us/blogs/rob_reynolds/archive/2010/09/21/the-evolution-of-package-management-for-net.aspx